
DetoxText: Text Detoxification Using Finetuned Encoder-Decoder Models
Date:
The project focuses on fostering safer online spaces by developing deep learning models that detect hate speech in various formats, including text, images, memes, videos, and audio content. The project repository can be found in the given link.
Objectives
- Develop deep learning models that accurately classify hate speech while minimizing false positives.
- Evaluate model performance with benchmarks and interpretability metrics.
- Address ethical and legal considerations in AI-powered content moderation.
Project Structure
The repository contains the following directories and files:
Directories
cleaned_data/contains the preprocessed datadata/contains the raw data that we download (paradetox.tsv)data_preprocessing/contains scripts for loading and preprocessing datasets.eval/includes evaluation routines and performance metrics.trainer/implements the training loop and model management.utils/provides utility functions used across the project.visualizatios/contains a folder with the plots used in our report.
Top-Level Files
README.md– Main project documentation.requirements.txt– Python dependencies.main_config.yaml– Configuration file for training and evaluation.main.py– Entry point to run the training pipeline.basic_running_scripts.sh– Shell script(s) to launch experiments.tokens.yaml– Contains token/API configuration if needed.starter.sh- Center script that runs the training
Getting Started
- Clone the repository:
git clone https://github.com/charafkamel/Deep_Learning.git cd Deep_Learning
Setup & Installation
- Create a virtual environment (optional)
python -m venv venv source venv/bin/activate # On Windows use `venv\Scripts\activate` - Install dependencies
pip install -r requirements.txt
Dataset
To train, evaluate and test the model we use the paradetox dataset from https://github.com/s-nlp/paradetox/blob/main/paradetox/paradetox.tsv. It is a parallel detoxification dataset containing over more than 12,000 toxic-neutralized sentence pairs. Collected via crowdsourcing using Reddit, Twitter and Jigsaw. Ensures semantic similarity and fluency while removing toxicity.
Model Architecture
We use the Qwen3-0.6B model and the T5-base model as our primary architectures, representing decoder-only and encoder-decoder architectures respectively.
Training
This project supports Supervised Fine-Tuning (SFT) and Reinforcement Learning (GRPO) training for both encoder-decoder (Seq2Seq) and decoder-only models. Below are the available training configurations and how to use them.
Available Training Setups
We support five different training setups:
1. Encoder-Decoder (Seq2Seq) Models
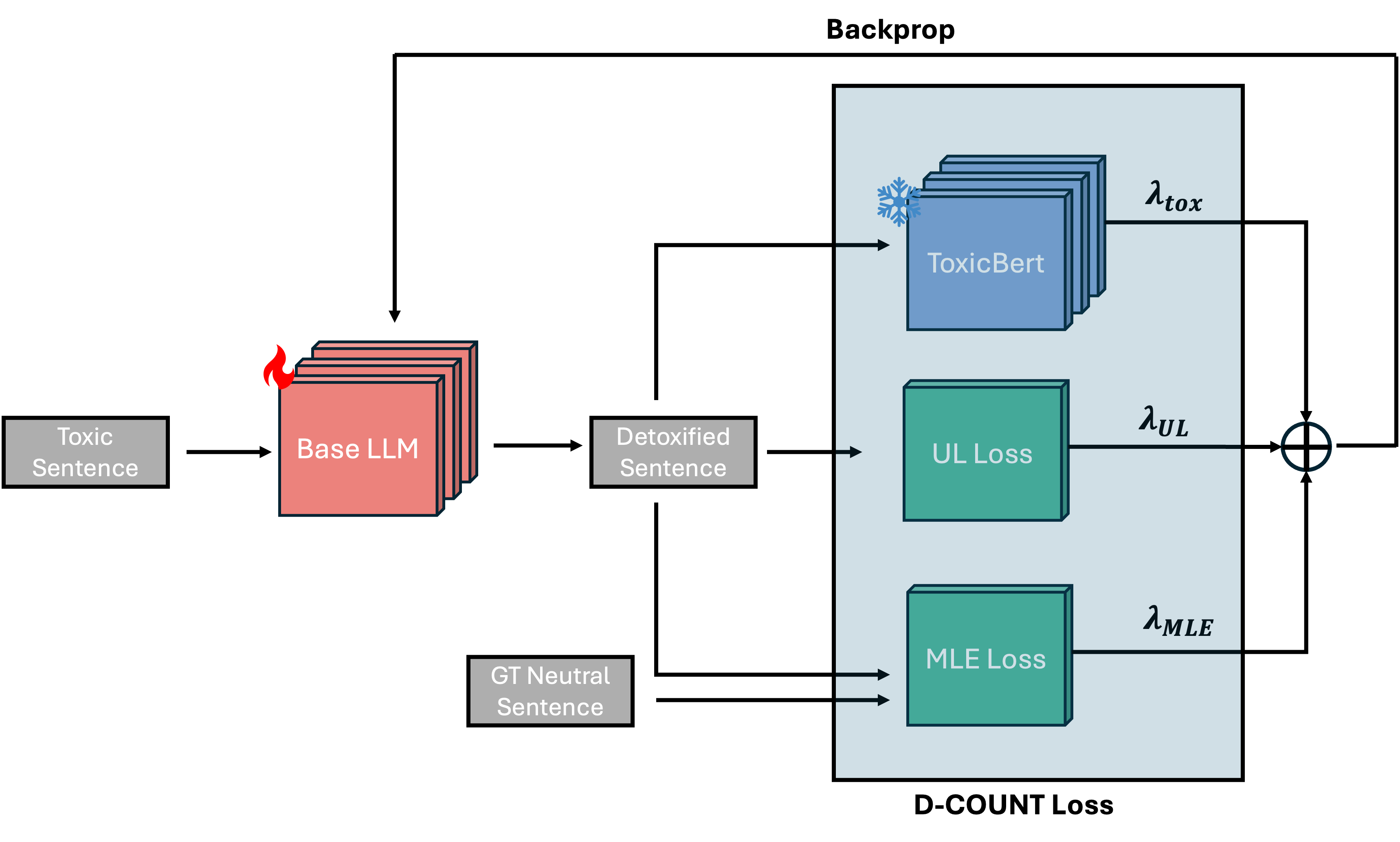
--base: Train using standard cross-entropy loss--count: Train using our custom loss function
2. Decoder-Only Models
--base_generative: Train using standard cross-entropy loss--count_generative: Train using our custom loss function--rl: Train using Reinforcement Learning (GRPO) with our custom reward function
How to Train
Run the following command with the appropriate flag:
python main.py --base # Seq2Seq with standard loss
python main.py --count # Seq2Seq with custom loss
python main.py --base_generative # Decoder-only with standard loss
python main.py --count_generative # Decoder-only with custom loss
python main.py --rl # Decoder-only with RL (GRPO)
Evaluation
To evaluate model performance:
python eval/eval.py
This will run the evaluation script on all of the saved models under the defined hugging-face account (defined in main_config.yml with the “hf_username” parameter). The results will be saved in a csv under
Run everything
It is also possible to run all of the training using the starter script:
./starter.sh
This will launch all 5 training jobs in parallel. After those are finished running, we might launch the evaluation script
Contributors
- Kamel Charaf
- Efe Tarhan
- Mahmut Serkan Kopuzlu